Chapter 8 - Graph-Shortest Paths
1 Shortest Paths

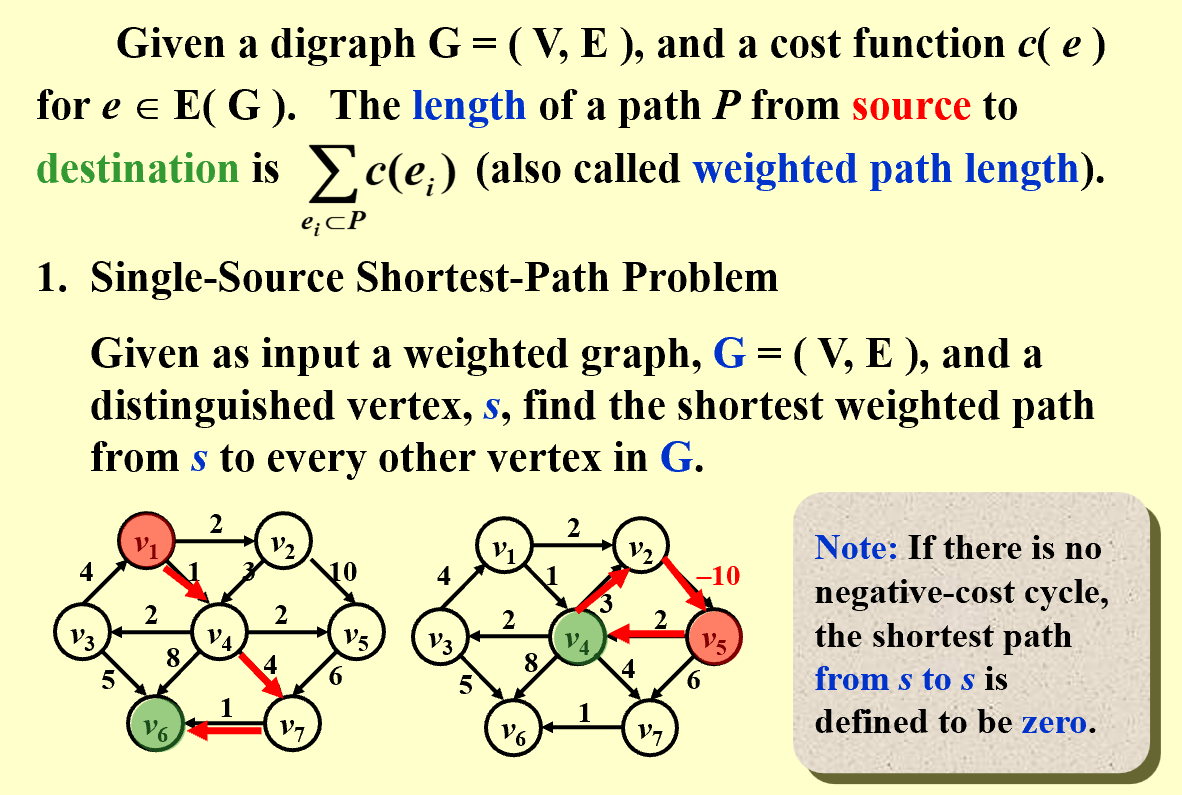
如果图中存在负权环(环上所有边的代价之和为负数),则最短路径不存在 —— 因为可以绕环无限次,让路径长度无限减小。
若图中无负权环,定义源点到自身的最短路径长度为 0。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| void Unweighted(Table T) {
int CurrDist;
Vertex V, W;
// 按距离从小到大处理所有顶点
for (CurrDist = 0; CurrDist < NumVertex; CurrDist++) {
// 找到所有距离为CurrDist且未处理的顶点
for (each vertex V) {
if (!T[V].Known && T[V].Dist == CurrDist) {
T[V].Known = true;
// 更新邻接点的距离
for (each W adjacent to V) {
if (T[W].Dist == Infinity) {
T[W].Dist = CurrDist + 1;
T[W].Path = V;
}
}
}
}
}
}
|
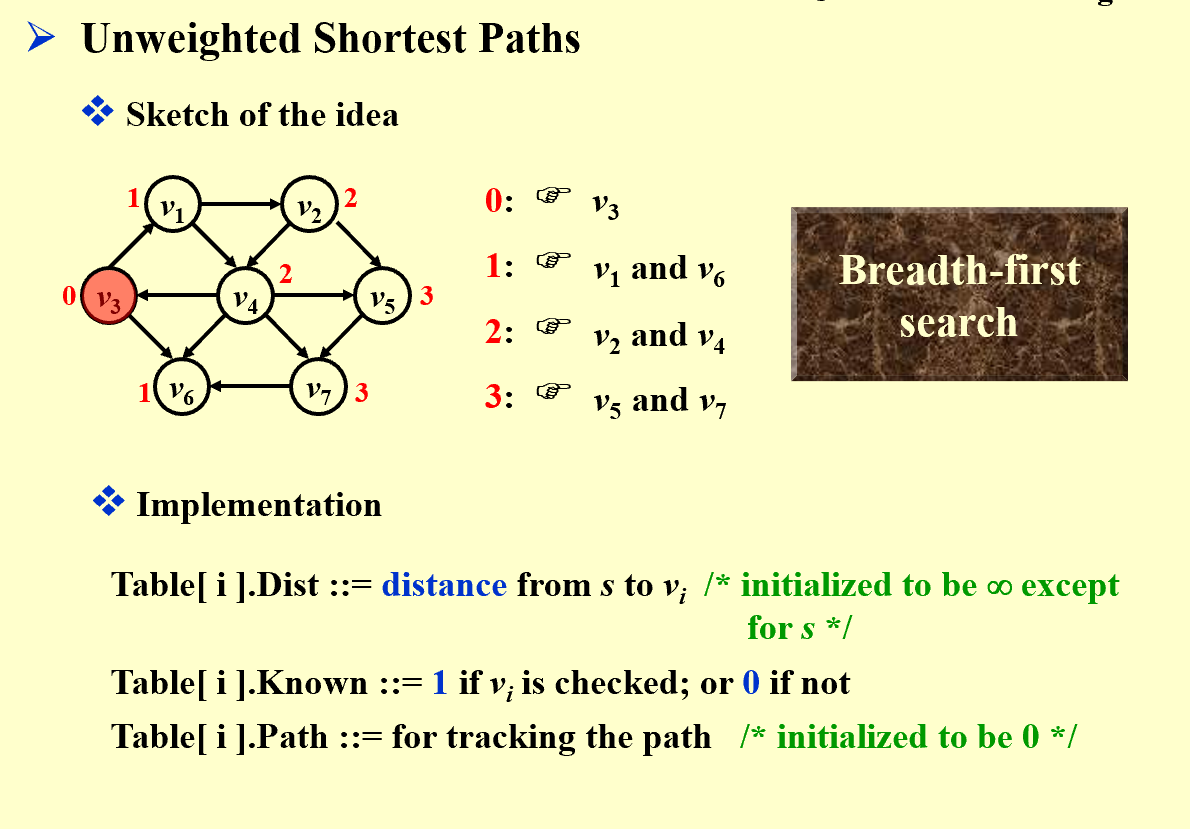
初始状态:T[v3].Dist = 0,其他顶点的 Dist = Infinity,所有 Known = false。
CurrDist = 0:
中间循环扫所有顶点,找到 Dist=0 且 Known=false 的 v3。
把 T[v3].Known 设为 true。
看 v3 的邻接点(比如 v1、v6),它们的 Dist 是 Infinity,所以:
T[v1].Dist = 0+1 = 1,T[v1].Path = v3;
T[v6].Dist = 0+1 = 1,T[v6].Path = v3。
CurrDist = 1:
中间循环扫所有顶点,找到 Dist=1 且 Known=false 的 v1 和 v6。
先处理 v1:标记为 Known=true,看它的邻接点 v2、v4,把它们的 Dist 设为 1+1=2,Path 设为 v1。
再处理 v6:同理标记并更新它的邻接点。
CurrDist = 2:
找到 v2、v4,处理它们的邻接点 v5、v7,把距离设为 3。
CurrDist其实就代表了是第几层,本质上就是广度优先搜索
但是对于一条链,比如
找dist为0的点,遍历一遍,找到
找dist为1的点,遍历一遍,找到
找dist为2的点,遍历一遍,找到
…
所以复杂度是,太大了
优化:使用队列,对于每一层的每个顶点,把它的下一层,即它邻接的点入队
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| void Unweighted(Table T) {
Queue Q;
Vertex V, W;
Q = CreateQueue(NumVertex);
MakeEmpty(Q);
Enqueue(S, Q); // 源点入队,源点的Dist是0
while (!IsEmpty(Q)) {
V = Dequeue(Q);
T[V].Known = true; // 此标记非必需,因为每个顶点仅入队一次
// 更新所有未访问的邻接点
for (each W adjacent to V) {
if (T[W].Dist == Infinity) {
T[W].Dist = T[V].Dist + 1;
T[W].Path = V;
Enqueue(W, Q);
}
}
}
DisposeQueue(Q);
}
|
时间复杂度为(每个顶点入队 / 出队 1 次,每条边被处理 1 次)
2 Dijkstra’s Algorithm
这是最经典的带权图最短路径算法,基于贪心策略,要求所有边的权值非负。
- 定义集合 :包含源点 和所有已经找到最短路径的顶点。
- 对于不在 中的顶点 ,定义
distance[u]:从 出发,只经过 中的顶点到达 的最短路径长度。
- 算法步骤:
- 初始化 ,
distance[s]=0,其他顶点为无穷大。
- 重复直到 包含所有顶点:
- 选择不在 中且
distance 最小的顶点 ,加入 (贪心选择)。
- 对 的每个邻接点 ,更新
distance[v] = min(distance[v], distance[u]+c(u,v))。
证明
假设选择 加入 时,distance[u] 不是 到 的最短路径长度。那么存在一条更短的路径 ,其中 不在 中。此时 distance[w] < distance[u],与” 是不在 中距离最小的顶点”矛盾。因此贪心选择是正确的。
伪代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| void Dijkstra(Table T) {
Vertex V, W;
for (;;) {
V = smallest unknown distance vertex;
if (V == NotAVertex) break;
T[V].Known = true;
for (each W adjacent to V) {
if (!T[W].Known) {
if (T[V].Dist + Cvw < T[W].Dist) {
T[W].Dist = T[V].Dist + Cvw;
T[W].Path = V;
}
}
}
}
}
|
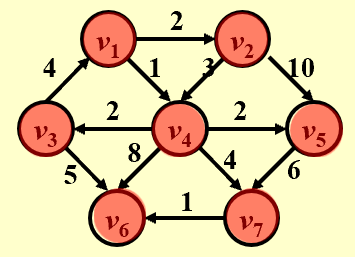
例如
带权图结构:
算法执行过程:
- 初始:v1.Dist=0,其他为∞。选v1加入S,更新v2.Dist=2,v4.Dist=1。
- 选v4(最小未处理)加入S,更新v3.Dist=3,v5.Dist=3,v6.Dist=9,v7.Dist=5。
- 选v2(最小未处理)加入S,v5当前Dist=3 < 2+10=12,不更新。
- 选v3(最小未处理)加入S,更新v6.Dist=min(9,3+5)=8。
- 选v5(最小未处理)加入S,v7当前Dist=5 < 3+6=9,不更新。
- 选v7(最小未处理)加入S,更新v6.Dist=min(8,5+1)=6。
- 选v6加入S,算法结束。
2.1 Implementation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
| #include <stdio.h>
#include <stdlib.h>
#include <limits.h>
#define Infinity INT_MAX
#define NotAVertex -1
#define MaxVertexNum 100
typedef struct {
int Dist;
int Known;
int Path;
} TableEntry;
typedef TableEntry Table[MaxVertexNum];
typedef int Vertex;
typedef int Weight;
typedef struct AdjNode {
Vertex adjvex;
Weight weight;
struct AdjNode *next;
} AdjNode;
typedef struct {
AdjNode *head[MaxVertexNum];
int vertexNum;
int edgeNum;
} Graph;
void InitTable(Vertex start, Graph *G, Table T) {
for (int i = 0; i < G->vertexNum; i++) {
T[i].Dist = Infinity;
T[i].Known = 0;
T[i].Path = NotAVertex;
}
T[start].Dist = 0;
}
Vertex FindMinDist(Table T, Graph *G) {
int minDist = Infinity;
Vertex minV = NotAVertex;
for (int i = 0; i < G->vertexNum; i++) {
if (!T[i].Known && T[i].Dist < minDist) {
minDist = T[i].Dist;
minV = i;
}
}
return minV;
}
void Dijkstra_Basic(Graph *G, Vertex start, Table T) {
InitTable(start, G, T);
Vertex V, W;
AdjNode *p;
for (;;) {
V = FindMinDist(T, G);
if (V == NotAVertex) break;
T[V].Known = 1;
p = G->head[V];
while (p != NULL) {
W = p->adjvex;
if (!T[W].Known) {
if (T[V].Dist + p->weight < T[W].Dist) {
T[W].Dist = T[V].Dist + p->weight;
T[W].Path = V;
}
}
p = p->next;
}
}
}
|
外层循环执行 | V | 次(每个顶点处理 1 次)
每次FindMinDist是 O (|V|)
所有边总共被处理 1 次(O (|E|))
总时间:
(稠密图中 | E|≈|V|²,这个复杂度是最优的)
可以用堆来优化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
typedef struct {
int dist;
Vertex v;
} PQNode;
typedef struct {
PQNode data[MaxVertexNum * 10];
int size;
} MinHeap;
void InsertHeap(MinHeap *heap, int dist, Vertex v) {
int i = ++heap->size;
while (i > 1 && dist < heap->data[i/2].dist) {
heap->data[i] = heap->data[i/2];
i /= 2;
}
heap->data[i].dist = dist;
heap->data[i].v = v;
}
PQNode DeleteMin(MinHeap *heap) {
PQNode minNode = heap->data[1];
PQNode lastNode = heap->data[heap->size--];
int i = 1, child;
while (i * 2 <= heap->size) {
child = i * 2;
if (child != heap->size && heap->data[child+1].dist < heap->data[child].dist)
child++;
if (lastNode.dist <= heap->data[child].dist)
break;
heap->data[i] = heap->data[child];
i = child;
}
heap->data[i] = lastNode;
return minNode;
}
void Dijkstra_PriorityQueue(Graph *G, Vertex start, Table T) {
InitTable(start, G, T);
MinHeap heap;
heap.size = 0;
InsertHeap(&heap, 0, start);
Vertex V, W;
AdjNode *p;
PQNode node;
while (heap.size > 0) {
node = DeleteMin(&heap);
V = node.v;
if (T[V].Known) continue;
T[V].Known = 1;
p = G->head[V];
while (p != NULL) {
W = p->adjvex;
if (!T[W].Known && T[V].Dist + p->weight < T[W].Dist) {
T[W].Dist = T[V].Dist + p->weight;
T[W].Path = V;
InsertHeap(&heap, T[W].Dist, W);
}
p = p->next;
}
}
}
|